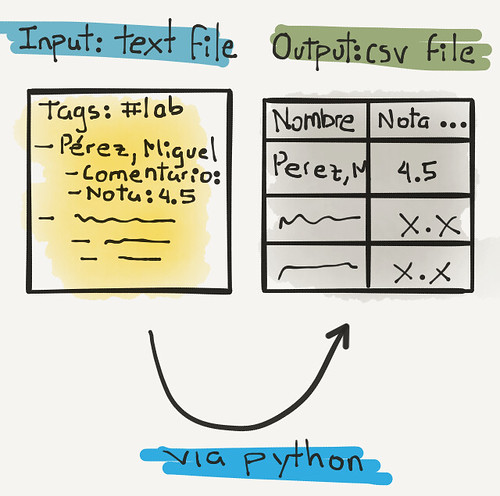
Despite all the tools and applications at my disposal, I like to write my comments, feedback and grade the lab reports I get from my students using plain text files. To be precise, markdown formatted plain text files md.
I typically write in a plain text file using nvalt or textmate as my text editor. With the help of a TextExpander snippet I print out the class list and the other fields I must fill out, typically a general comment/feedback and the grade. The snippet produces something like this:1
tags:#vision,#lab
- Pérez Ramos, Miguel A.
- Comentario:
- Nota:
- Beleño Hernández, Liliana P.
- Comentario:
- Nota:
... Other parts look the same ...
After filling it out I get something like the following:
tags:#vision,#lab
- Pérez Ramos, Miguel A.
- Comentario: El informe está completo y bien argumentado. Se demuestra que se realizó la práctica a cabalidad. Concluye adecuadamente y cita las referencias consultadas.
- Nota: 5.0
- Beleño Hernández, Liliana P.
- Comentario: El informe comienza bien, pero termina abruptamente. No se mencionan los aspectos relacionados con la lectura y tampoco se evidencia adecuadamente los resultados de la práctica. No hay bibliografía.
- Nota: 3.5
- Carrascal Mendez, Martín S.
- Comentario: El informe es adecuado y cumple con el objetivo de la práctica.
- Nota: 5.0
This is easy to fill out, looks nice and is well formated. I can preview it - if I want – in Marked or in any other markdown previewer. But the truth is, I’m fine viewing it just like that in plain text. The tedious part comes when I need to copy the grades from this file to a spreadsheet.
This is where automating the boring stuff in python makes this a fun and interesting problem to spend an evening solving with a script. The following script takes an input text file formatted like the one previously shown.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 | |
The usage is very simply, you just call the script grades2csv.py with the file you want to process. If you don’t specify where the output should go (-o option) it defaults to the same path as the input text file.
I didn’t bother on avoiding overwriting an existing csv file with the same name. I never name two text files with grades the same way.
About a year ago, I found out about this awesome trick of setting up a REMatcher class so that I can have an object that saves the matched string and returns True when it matches the regex. I’ve never gone back to implementing other regex paraphernalia in python. This works and I stick with it.
The script looks for three different matches in every line of the input file. One for a line that starts with a dash (^-(.*$)), capturing the name of the student (m.group(1)). The second, that matches the word Comentario("^\t.*-.*Comentario:(.*$)") and captures the comment, and the third that captures the grade ("^\t.*-.*Nota:\s*(\d.*$)"). If the grade is not captured, then not a single item is written to the csv file (wr.writerow(List)).
If everything is well formated in the input file. The output is a nicely formatted csv file:
"Nombre","Nota","Comentario"
" Pérez Ramos, Miguel A.","5.0"," El informe está completo y bien argumentado. Se demuestra que se realizó la práctica a cabalidad. Concluye adecuadamente y cita las referencias consultadas."
" Beleño Hernández, Liliana P.","3.5"," El informe comienza bien, pero termina abruptamente. No se mencionan los aspectos relacionados con la lectura y tampoco se evidencia adecuadamente los resultados de la práctica. No hay bibliografía."
" Carrascal Mendez, Martín S.","5.0"," El informe es adecuado y cumple con el objetivo de la práctica."
" Piñeres De La Rosa, Néstor N.","4.7"," El marco teórico apunta a lo necesario, pero con las citas correspondientes. Muy bien por utilizar otras imágenes. Los comentarios son oportunos. Una discusión un poco más extensa sobre los distintos tipos de filtros que se implementaron en la última parte es deseable, ""prewitt"", ""sobel"", etc."
" Daza Beltran, Juan A.","3.5"," El informe se ajusta a lo mínimo. Debería tener una discusión de resultados más extensa u observaciones del proceso de filtrado con diferentes filtros. Termina abruptamente. No hay bibliografía."
Which looks like this when viewed as a spreadsheet:

You might be wondering, but why go through all this trouble. Because I can, but mostly because I find spreadsheets useful, but I don’t like typing data into them. I find it more productive to write continuously in a plain text file. I can use Textexpander and other tools more easily. And finally, why not let the computer do the work it’s supposed to do - I’m no monkey.
-
These are not the real names of my students.↩